폴더 기능을 구현할 일이 생겼다.
폴더 안의 폴더가 있을 수 있는 트리 구조이다.
트리 구조를 DB 에 저장하기 위한 대표적인 4가지 패턴이 있다.
- Adjacency list
- Nested set
- Path enumeration
- Closure table
진행 중인 프로젝트에서 TypeORM 을 사용하고 있는데,
TypeORM 에서는 트리 구조에 대한 4가지 패턴을 라이브러리 단에서 전부 지원하고 있으므로
어떤 패턴을 선택해야할 지 결정해야 했다.
조사를 하면서 tree 구조에 대해 아주 잘 설명되어 있는 이 PPT 가 굉장히 큰 도움이 됐다.
각 특징을 간략하게 정리해보면 다음과 같다.
1. Adjacency list
parentId 컬럼만 들고 있으면 되는 방식이다.
자신의 직계 부모나 직계 자식은 쉽게 조회할 수 있다.
다만, 부모의 부모의 부모 혹은 자식의 자식의 자식..
이런 deep tree 에서는 sql 쿼리 시 recursive 하게 구현해야해서 성능 저하 문제가 있다;;
2. Path enumeration
루트부터 해당 노드까지의 경로를 문자열로 저장하는 형태다.
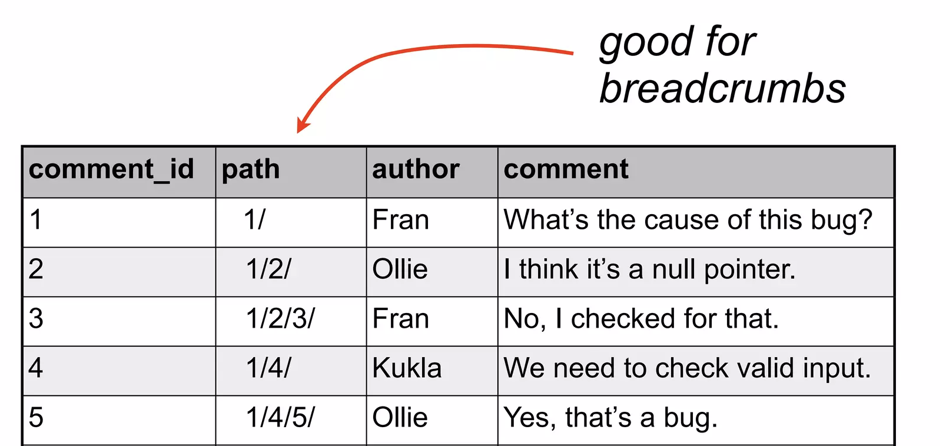
위 캡쳐를 보면 "good for breadcrumbs" 라는 표현이 있는데
breadcrumbs 란 사용자가 특정 위치에 있는 동안, 계층적 구조의 상위 경로를 표시하는 UI 패턴을 의미한다.

Path enumeration 패턴은 계층 구조를 한 컬럼에다가 저장하니까 breadcrumbs 에 유용하다.
이 패턴의 단점은 path 만 저장하고 부모 ID 를 따로 저장하지 않기 때문에 직계 자식을 가져올 때 복잡하다.
3. Closure table
"closure" 라고 칭하는 many-to-many 테이블을 만들어서 모든 부모/자식 관계를 저장해두는 방식이다
자기 자신으로의 연결 정보조차 저장한다. (ancestorId: 1, descendantId: 1)
모든 관계를 저장하다보니 o(n^2) 만큼의 저장 비용이 든다

재미있는건 새로운 자식 노드를 추가할 때
closure table 에서 부모의 연결 관계를 SELECT 해와서 그대로 추가해준다.
length 컬럼을 추가하여 ancestor-descendant 사이의 depth 를 저장할 수도 있다.
이건 breadcrumbs UI 에서 N번째 경로까지만 제한해서 가져오고 싶을 때 좋을 것 같다.
현재 노드가 속한 모든 상위 경로를 조회해올 필요는 없으니,
where length=5 세팅해서 조회해오면 UI 에서 필요한 5개의 상위경로만 뽑아올 수 있을 것이다.

결론
최종적으로 나는 조회를 빠르게 하기 위해 공간을 희생하는 전략인 Closure Table 패턴을 선택했다.
어차피 어떤 패턴을 선택하든 TypeORM 에서는 각 패턴에 대한 메소드를 전부 제공하고 있다.
그렇기에 라이브러리 가져다 쓰는 입장에서는 구현에는 차이가 없지만 조회 속도를 고려하자면 Closure Table 패턴이 적합했다.
이유는 폴더 구조는 삽입과 삭제보다는 조회가 주를 이루는 구조이다.
Adjacenecy List 패턴의 경우,
Subtree 를 조회할 때 Adjacency List 의 경우는 위에서 말했다시피 recursive 하게 left join 을 해야한다.
하지만 Closure 테이블의 경우 ancestor 와 descendant 의 모든 관계를 담고 있으므로 재귀 작업 없이 조회 한 번이면 끝난다.
(where ancestorId = 1)
적합한 패턴을 결정하기 위한 지표로 아래 표가 도움이 됐다.
